
Teaching AR to understand the world (ISMAR & AWE 2)
Dadada, here, little computer! This is a teddy bear! Dadadada, this is a bottle! This is a skateboard, … but it is very dangeroooous! When communicating with computers and AI… we feel like “they” are still little babies, starting at zero. Also, augmented reality applications are often still too dumb to really help us out. Time to change this! A glimpse into the near future at ISMAR conference in Munich today.
During the great double feature week in Munich with AWE and ISMAR there was a lot to see and digest. One of my favorite papers and demos during research-focused ISMAR conference, was the “mask fusion” entitled approach to combine different fields for a smarter AR experience!
Unfortunately, I’ve been too busy (which is a good thing) with work and life balance, so it’s a bit delayed on ISMAR news. But still worth a post, I’d say. By the way: from now on, augmented.org is on a new server, also comes with certified httpS and has a fun twitter widget for quick news on a daily basis. So you see, it’s all for the best waiting a bit longer. Now, let’s jump in!
The Machine learns to understand the world
As of today, the common tracking algorithms for AR focus on camera pose estimation and movement. They assume a static scene and if they deliver a scene reconstruction it’s mostly a “growing” scan that also expects a static world. The returned values are only a geometrical description. No further knowledge about the scene exists at this point. The system does not know what it’s front of the camera. Is it a table? A human or a plant? Today’s system (like the HoloLens Toolkit or ARCore/Kit) help out a bit to identify “suitable” flat surfaces to place a virtual character or hang up a virtual frame to a real wall. But identifying moving (or moveable) objects is still rather untouched. A wheeled coffee table is not identified to place the virtual cake on it… Moving objects within the space are typically seen as noise and filtered out. Even if updating the mesh is fast enough in real-time, we still don’t know what that pixel junk is… if we go the other way round and track a marker, a physical object, etc. we would usually only track this and forget about the space around. Our origin / real world anchor would move through the world and not care about it’s surroundings.
Semnatic Knowledge to really integrate Augmented Objects
AR has still different challenges to overcome. Let’s leave the glasses hardware development aside for now… still, tracking itself is too limited, as seen above. We need to follow dynamic objects and know what they represent. In other fields we have pieces of this already (like Google Lens or other Machine Learning toolsets) – but not yet combined. The mask fusion approach from Lourdes Agapito and Martin Rünz from University College in London show us how all this combined could boost AR in their demo!
Mask Fusion approach for a full AR experience
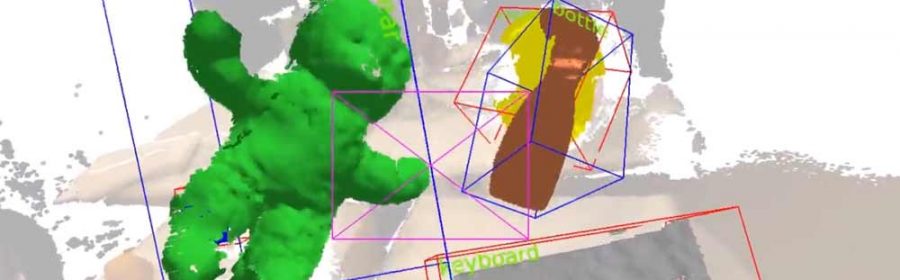
They use a RGBD camera to scan the real world and deliver a color and depth map. The system estimates the camera pose and an image processing (in 2D) will run over each frame to try to identify objects (using a pre-trained open database for object classes). Using the depth sensor in combination it is even possible for them to follow different real world instances of the same object: e.g. two beer bottles that look alike can still be tracked in 6DOF.

A crucial move is that they do not need to train their system with a specific (and possibly) small set of objects. No 3D shapes or models are stored beforehand. Other tools like Vuforia or Fraunhofer’s VisionLib would require the user to store an accurate 3D model of to-be-detected objects. This is needed to have an accurate overlay, but for general purposes very restricting. Other approaches seen before (I’ve reported on Microsoft’s research on “Interactive 3D Labeling and Learning”) needed user interaction or manual classification.
The “mask fusion” approach does not require any labeling or semi-interactive processes, which is great. It even allows detection of humans and body parts like hands, which might come in handy for interaction with AR elements…
Talking about use cases
The research team talks of multiple use cases, focusing on robotic vision to help out our robo friends to move inside the real world without breaking stuff, like soft human bodies: if they detect us within their acting space, they might want to stop running or welding, etc.

On the other hand they show a more human-centered scenario where food is identified and pop-up info notify us of nutrition value of an apple, a cake… This could be any kind of context dependent interaction! Thanks to the hand / gesture detection and the correct estimate of a touch, great interface concepts can be imagined: all using an inside-out camera system to learn about the world and it’s (dynamically moving) objects inside. But the most fun demo is seen in their video (below): the system identifies a skateboard and automatically places the virtual character on-top, before pushing it – the character sticking solidly on the deck.
This mini demos shows a great and urgent step for context-aware AR helpers. Not only for storytelling, but also for everyday tasks and augmented AI avatars that can be integrated more naturally. Possibilities are endless!
The Technology behind
They use a typical SLAM approach, recreating the world along camera tracking. A 2D segmentation of the RGB image is feeding the MS-Coco object database. Coco is trained with 1.5 mio. objects in 80 categories.
Their system works partly in real-time (SLAM w/ 20-30 Hz). Object masking is currently stuck at 5 Hz and their high-end PC system (Nvidia GTX Titan X, intel Core i7, 35 GHz) cannot just yet be squeezed into a smartphone, but we can imagine this to happen and accelerate over time… Depth cams were supposedly dead for consumers (after Tango died), but I’m pretty sure there will a rebirth, once the rest of the components are ready and make sense together. (Apple could be integrating those in their upcoming models back-facing!)
So, overall it’s a great deal to automatically learn not only about shapes within the world but about entities, semantic relationships and what the objects actually are – while moving through the space! Combined with great AR glasses and some AI avatar or other helper tools this could become the game changer for our beloved augmented technology in the future!
The “mask fusion” paper and video can be found on their website.